Data Mining and Analysis using rtweet package
Census 2019 in Kenya
The 8th 2019 Population and Housing Census started from the night of 24/25th August 2019 and ended on 31st August 2019.
Census involved counting of people within the border of Kenya at a specific time. Census is an important process for the Govenrment as it provides evidence for proper planning and resource allocation, policy formulation and targeting of development plans. You can read more about the census here and here
Objectives
Here we shall
- Perform data mining using
rtweetpackage. - Determine unique words in #Censuskenya2019 tweets.
- Identify top user accounts in #Censuskenya2019 tweets.
- Plot time series of tweets including #Censuskenya2019.
Loading packages
library(rtweet) #twitter mining. All you need is a Twitter account (user name and password)
library(ggplot2) #plotting
library(dplyr) #pipes tidyverse
library(tidytext) # text mining
library(stopwords)
theme_set(theme_classic()) #setting theme to classic()Data Mining
I decided to use
rtweetgiven that it has more functionality compared to other twitter APIS likestreamR.
Kindly note the tweets harvested are based on who I follow on Twitter - it is a sample of what people are tweeting about #Censuskenya2019.
censusTweets <- search_tweets(q="#Censuskenya2019",n=10000, include_rts = FALSE, lang='en')
censusKE <- censusTweets #creating a copy
#glimpse(censusKE)The function search_tweet() returns tweets for the past 6-9 days. Unfortunately, I do not have a premium account - if you do try using search_30day() and the function requires env_name.
head(censusKE$text) #Top Tweet Unique Words## [1] "Shit. Well, this is happening <U+0001F447><U+0001F447>\n#someonetellknbs\n#KOTLoyals \n#censuskenya2019 \n#Kenya https://t.co/KTgAja1Z1B"
## [2] "Uncle @FredMatiangi juu #censuskenya2019 iliisha can we now use these reflector jackets kuendesha boda?"
## [3] "My mum was answering all the questions for my 15yo baby sister during #censuskenya2019 and lost her shit when she was asked if she has ever been pregnant <U+0001F923><U+0001F923><U+0001F923><U+0001F923><U+0001F923> 'SHE IS STILL A CHILD' like mum relax <U+0001F923><U+0001F923><U+0001F923><U+0001F923> https://t.co/U81jNvhmr9"
## [4] "Someone lied to Kenyans that the #censuskenya2019 was going to be different and results would be out within the shortest time, it's 2 weeks now since 31.08.2019, who else is counting?"
## [5] "When is @KNBStats planning to enumerate my family. @FredMatiangi\n#Censuskenya2019"
## [6] "Why is @CBKKenya pinging me to return old 1000K notes by deadline Sept. 30, yet the government recently did #censuskenya2019 and know I'm #JOBLESS?"Data Cleaning, Analysis and Visualization
When tweeting people use connectors and other wordss. tinytex package has a function known as stop_words() that has three lexicons for English stop words. Below are some stop words
head(stop_words)## # A tibble: 6 x 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a's SMART
## 3 able SMART
## 4 about SMART
## 5 above SMART
## 6 according SMARTWe use unnest_tokens() from tidytxt package
to convert any text from upper to lower case, remove punctuation, add unique ID. We clean the data, convert all the text to lower case and remove stop words
censusKE %>%
dplyr::select(text) %>%
unnest_tokens(Words, text) %>%
filter(!Words %in% stop_words$word) %>%
count(Words, sort=TRUE)## # A tibble: 83 x 2
## Words n
## <chr> <int>
## 1 censuskenya2019 9
## 2 https 3
## 3 t.co 3
## 4 business 2
## 5 family 2
## 6 fredmatiangi 2
## 7 government 2
## 8 kenyans 2
## 9 mum 2
## 10 results 2
## # ... with 73 more rowshttps appear as the 2nd highest word in #Censuskenya2019 - these represents links shared and we shall remove the https links from the text. Find and replace functions in base R include:
sub(pattern, replacement, text)replaces ONLY the first match in each element of a text vector.gsub(pattern, replacement, text)replacess ALL the matching patterns of a text vector.
censusKE$strpWords <- gsub("https.*", "", censusKE$text) #removing https.* linksBase R has various functions that are used for regular expression and they achieve different outcomes. A very gentle introduction to regular expression has been done by Jon Calder as a course on Swirl(). Installation can be done by either using
library(swirl)
install_course("Regular Expressions")
swirl()or alternatively downloading the latest version directly from Github
install_course_github("jonmcalder", "Regular_Expressions")
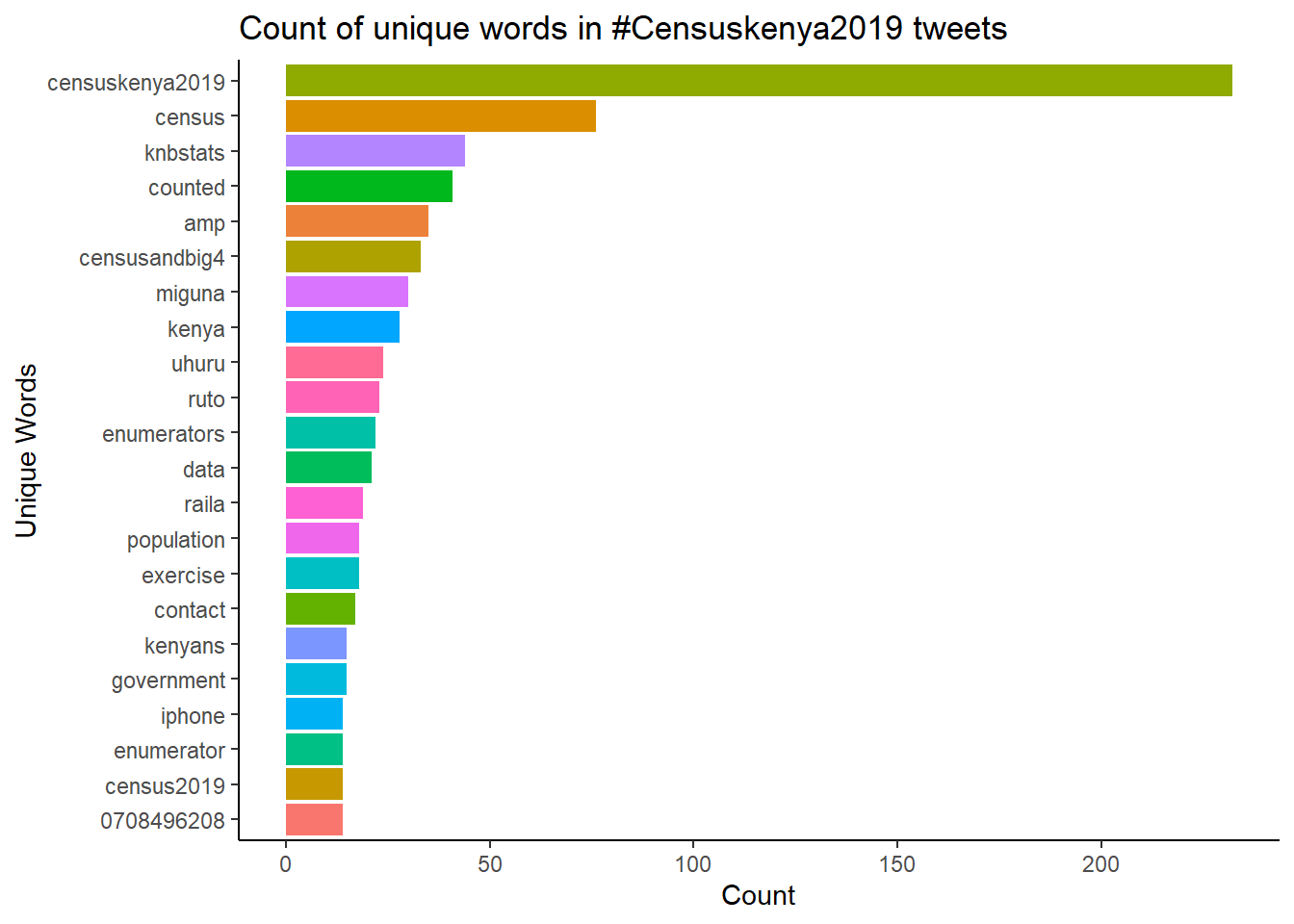
Unique words in #Censuskenya2019 tweets
censusKE %>%
dplyr::select(strpWords) %>%
unnest_tokens(word, strpWords) %>%
filter(!word %in% stop_words$word) %>%
count(word, sort = TRUE) %>%
top_n(20) %>%
ggplot(censusKE, mapping = aes(reorder(word, n), n)) +
geom_bar(stat = 'identity', aes(fill=word), show.legend = FALSE) +
coord_flip()+
labs(title = "Count of unique words in #Censuskenya2019 tweets ", x="Unique Words", y="Count")## Selecting by n
I was expecting to see KNBS : it is ranked number 3 on the list. Censusandbig4 agenda ranks at the top 5. Politician names such as Uhuru, Raila, Ruto are among the top 20 unique words being tweeted under the hashtag. Enumerators were hired to perform this excercise and hence these two words are among the top 20 unique words. However, a mobile number is among the top 20 words - am not sure if it is a hot line for census?
Top users in #Censuskenya2019 tweets
user_data() returns information of the users including screen names, location, creation time, description…
users <- users_data(censusKE)
users %>%
dplyr::select(location) %>%
unnest_tokens(Location, location) %>%
count(Location, sort =TRUE) %>%
top_n(10) %>%
ggplot(users, mapping = aes(reorder(Location, n), n)) +
geom_bar(stat = 'identity', aes(fill=Location), show.legend = FALSE) +
coord_flip() +
labs(title = "Location of users in #Censuskenya2019 tweets", x="Location", y="Count") ## Selecting by n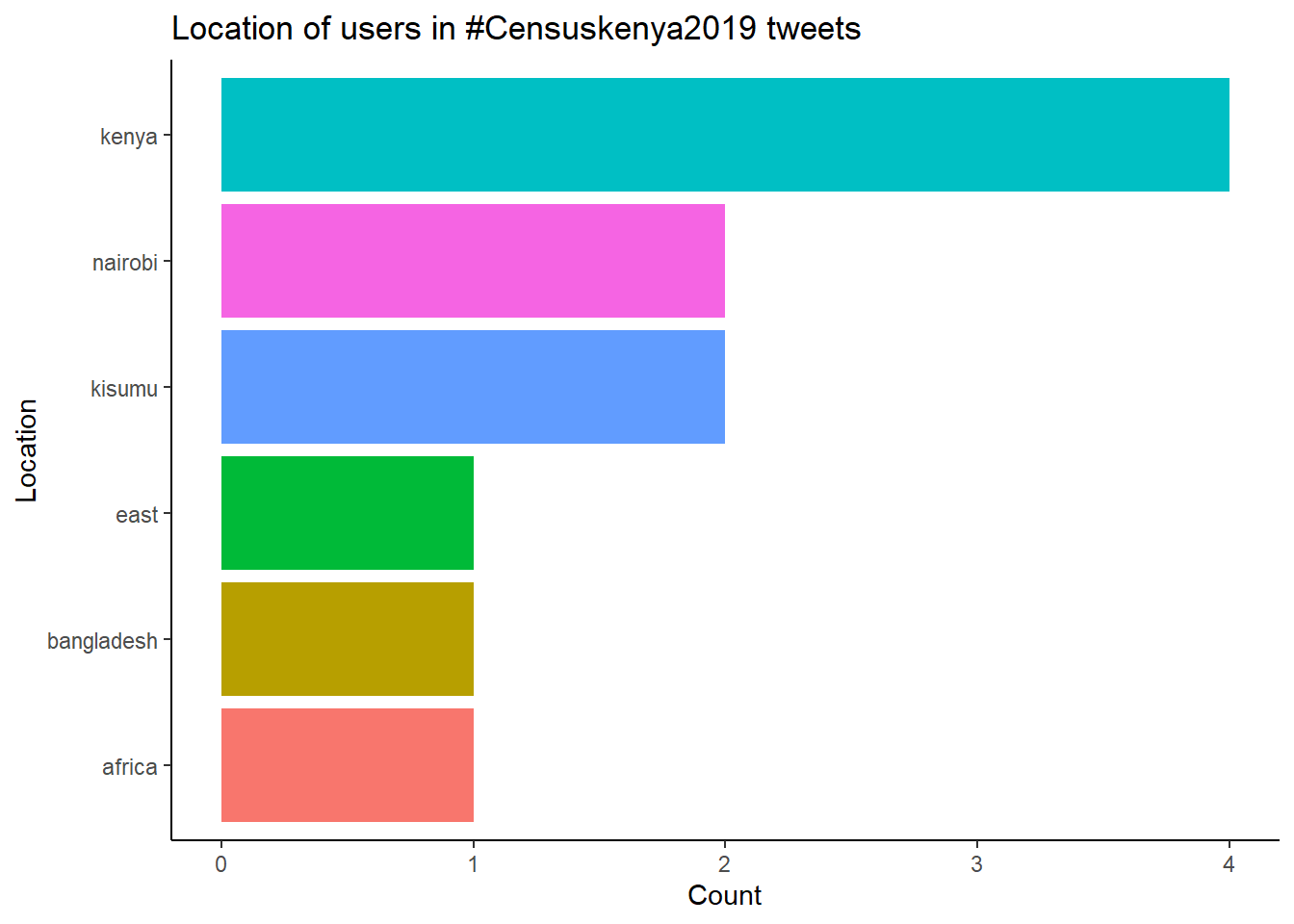 Most users were tweeting #Censususkenya2019 while in Kenya -especially Nairobi.
Most users were tweeting #Censususkenya2019 while in Kenya -especially Nairobi.
users %>%
dplyr::select(screen_name) %>%
count(screen_name, sort = TRUE) %>%
top_n(15) %>%
ggplot(users, mapping = aes(reorder(screen_name, n), n)) +
geom_bar(stat = 'identity', aes(fill=screen_name), show.legend = FALSE) +
labs(title="Top users in #Censuskenya2019 tweets", x="Screen Names", y="Count")+
coord_flip()## Selecting by n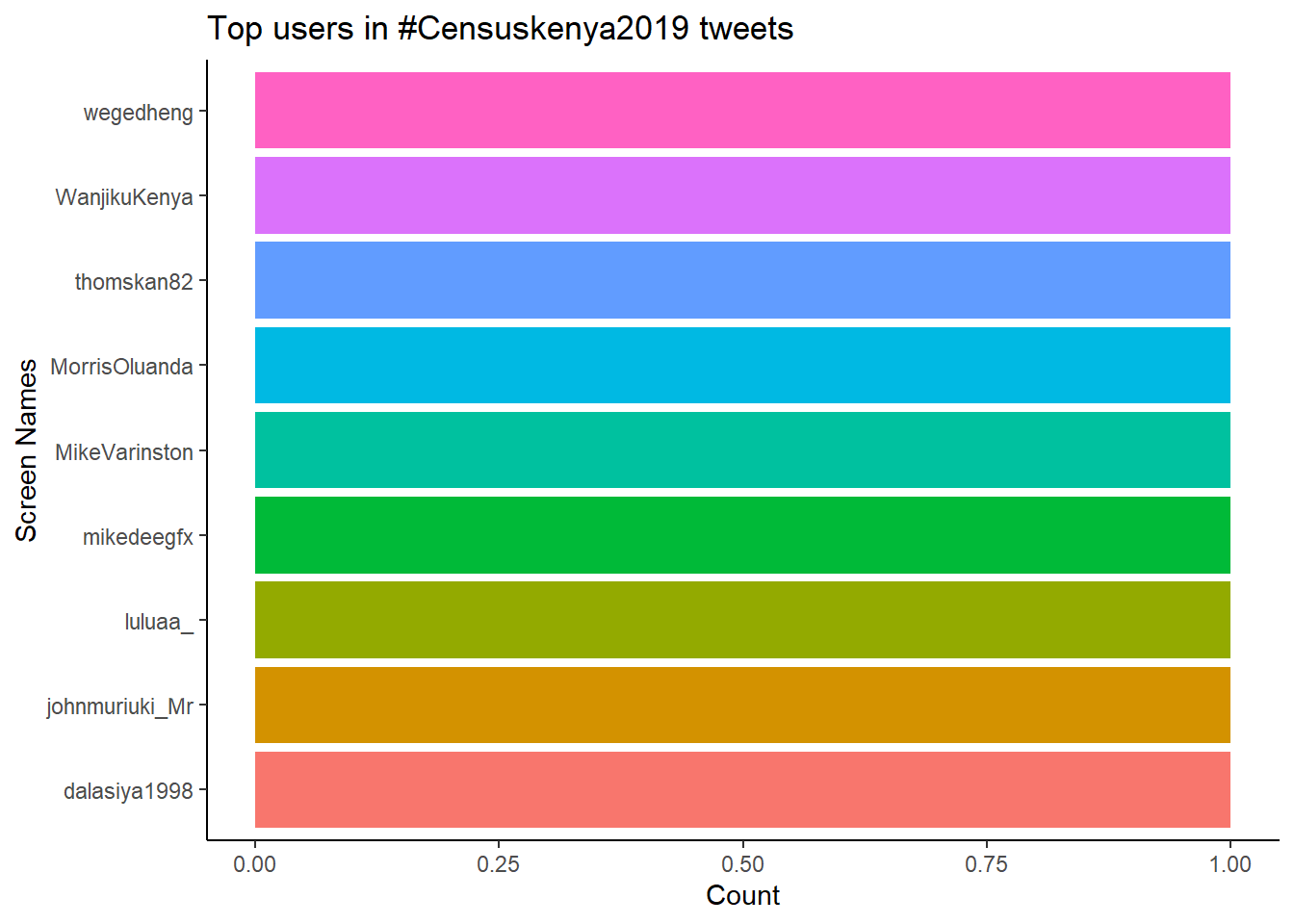
I was expecting KNBS account to be among the top looks like they’ve not been active in #Censuskenya2019 tweets.
Users with verified account in #Censuskenya2019 tweets.
table(users$verified)##
## FALSE
## 9Only 15 user accounts are veified in the users data object.
users %>%
count(verified, sort=TRUE) %>%
mutate(perc = n * 100/nrow(users)) ->verified.users
ggplot(verified.users, aes(x="", y=perc, fill=verified))+
geom_bar(width =1, stat = 'identity') +
coord_polar("y", start=0)+
labs(title = "Count of verified accounts in #Censuskenya2019 tweets")+
geom_text(aes(y=(0.67*perc), label=sprintf("%0.0f%%", round(perc,2))), color="white")+
theme_void()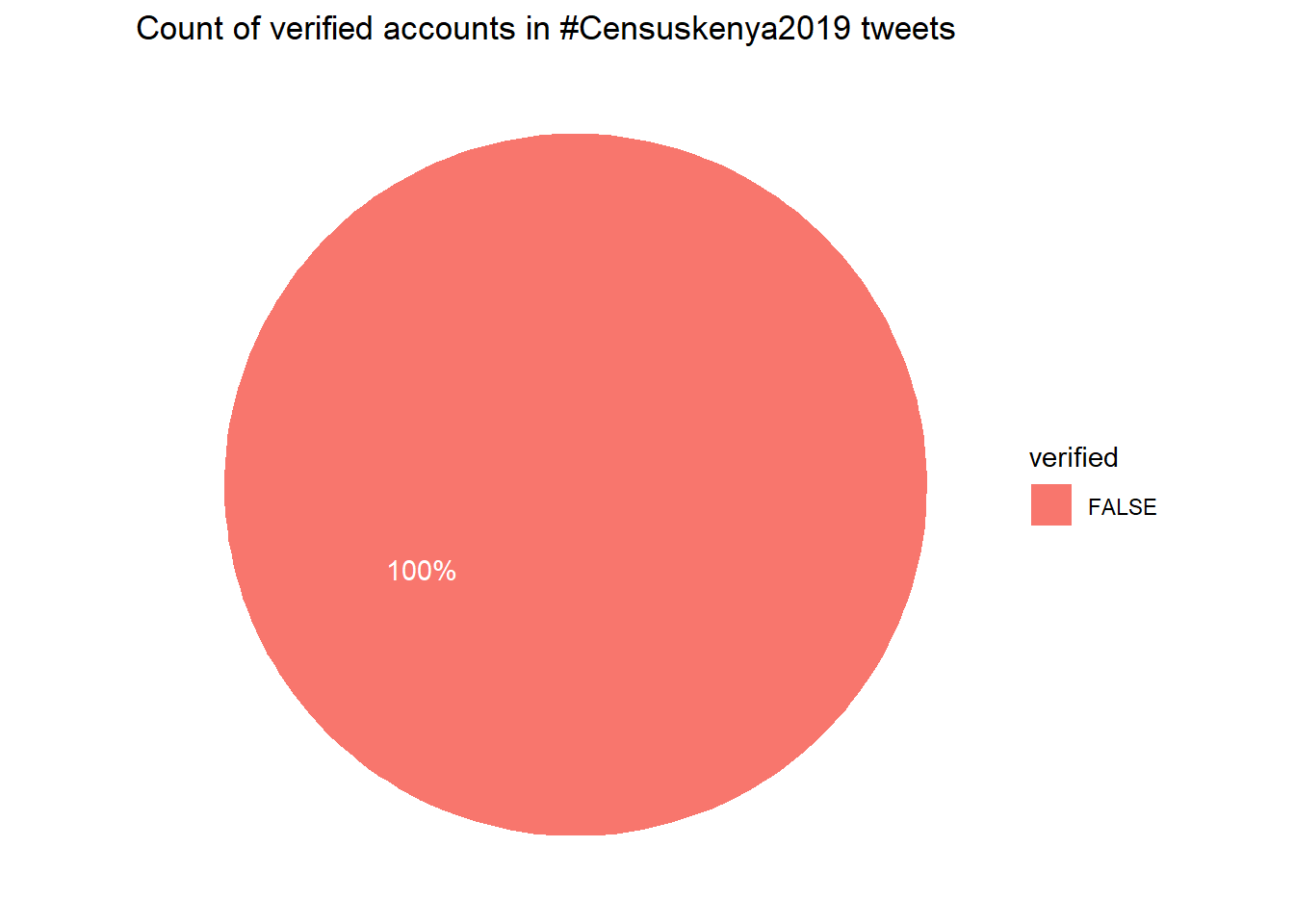
Time series of #Censuskenya2019 tweets
ts_plot(censusKE, by="days")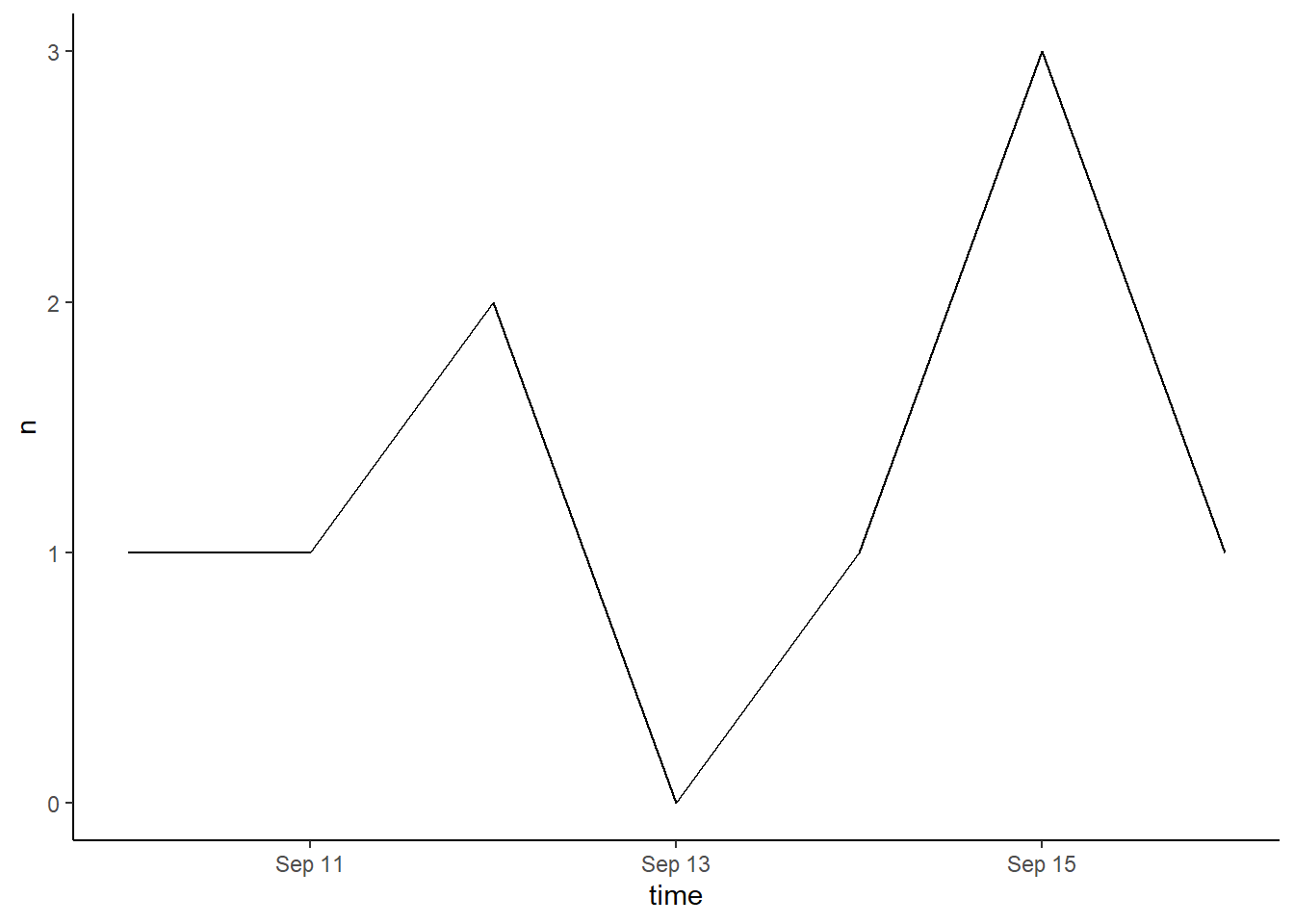
From the time series plot a lot of activity is seen on the last day of Census 2019 in Kenya i.e between 30th and 31st of August 2019.
